Tidying
Last updated: 2020-06-01
Checks: 7 0
Knit directory: requestival/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200529) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 8f40292. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: code/_spotify_secrets.R
Ignored: data/.DS_Store
Ignored: data/raw/.DS_Store
Ignored: data/raw/requestival_24_files/
Ignored: data/raw/requestival_25_files/
Ignored: data/raw/requestival_26_files/
Ignored: data/raw/requestival_27_files/
Ignored: data/raw/requestival_28_files/
Ignored: data/raw/requestival_29_files/
Ignored: data/raw/requestival_30_files/
Ignored: data/raw/requestival_31_files/
Ignored: output/01-scraping.Rmd/
Ignored: output/02-tidying.Rmd/
Ignored: output/03-augmentation.Rmd/
Ignored: output/04-exploration.Rmd/
Ignored: renv/library/
Ignored: renv/staging/
Untracked files:
Untracked: data/raw/requestival_29.html
Untracked: data/raw/requestival_30.html
Untracked: data/raw/requestival_31.html
Unstaged changes:
Modified: data/01-requestival-scraped.tsv
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/02-tidying.Rmd) and HTML (docs/02-tidying.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | f53e0cb | Luke Zappia | 2020-05-30 | Add tidying |
| html | f53e0cb | Luke Zappia | 2020-05-30 | Add tidying |
source(here::here("code", "setup.R"))Introduction
After the scraping process we have a the data about songs played during the Requestival in a nice tabular format. Let’s load it up and see what it looks like.
requestival <- read_tsv(
PATHS$scraped,
col_types = cols(
.default = col_character()
)
)Chunk time: 0.05 secs
This isn’t too messy at the moment but there are some things we could do to tidy it up. Let’s work through each of the columns and see if we need to do anything to them.
1 File
The first column contains the name of the file the song was scraped from. The file names have the form requestival_X, where X is a day in May 2020. We don’t really care about the file name but we do care about the day the songs were played so let’s take that part and create a new column.
requestival <- requestival %>%
mutate(Day = str_remove(File, "requestival_")) %>%
mutate(Day = paste0("2020-05-", Day))
requestivalChunk time: 0.63 secs
2 Time
The time each song was played is currently a string with the form hh:mmpp (where pp is am or pm). It would be better to have this has a time object so let’s do that conversion.
requestival <- requestival %>%
mutate(Time = parse_time(Time, "%I:%M%p"))
requestivalChunk time: 0.66 secs
Now all our times are hms objects and that have the form HH:MM:ss. Our days and times are now in nice formats let’s combine them into a single datetime. This is pretty easy to do, we just covert our day string to a datetime object and then add on our time.
requestival <- requestival %>%
mutate(DateTime = as_datetime(Day, tz = "Europe/Berlin") + Time)
requestivalChunk time: 0.65 secs
You might notice that the times are in the CEST timezone. This is because the HTML pages were downloaded in Europe and the Triple J website is clever enough to display times using your local timezone. It doesn’t really make sense to use European times for a dataset from an Australian radio station so let’s convert them to the Australian east coast timezone that Triple J broadcasts in.
requestival <- requestival %>%
mutate(DateTime = with_tz(DateTime, "Australia/Sydney"))
requestivalChunk time: 0.64 secs
3 Song
The song name column is made up of strings. This is probably what we want but let’s do a quick check to see if we have any weird characters left over from the HTML.
song_chars <- requestival$Song %>%
str_extract_all(boundary("character")) %>%
unlist() %>%
sort() %>%
unique()Chunk time: 0.07 secs
These are the unique characters we have in the song names: , , _, -, ,, ;, :, !, ?, ., ’, ", (, ), [, ], {, }, *, /, &, #, %, +, |, $, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a, A, à, Æ, b, B, c, C, d, D, e, E, é, f, F, g, G, h, H, i, I, j, J, k, K, l, L, m, M, n, N, o, O, p, P, q, Q, r, R, s, S, t, T, u, U, v, V, w, W, x, X, y, Y, z, Z, 그, 대, 로, 른, 리, 방, 오, 옳, 은, 자, 향, 殯, 舟
Most of these letters in the standard Latin alphabet, numerals or standard punctuation but there are also a few different kinds of white space, some accented letters and what I think are Korean characters.
Let’s make a table of these characters with their Unicode descriptions to try and work out what they are.
song_chars %>%
map_int(utf8ToInt) %>%
Unicode::u_char_info() %>%
mutate(Character = song_chars) %>%
select(Character, Code, Name)Chunk time: 0.14 secs
I have quickly checked some of these and it looks like they are correctly part of song names so I am going to leave them. I will replace the non-breaking spaces with regular spaces though.
requestival <- requestival %>%
mutate(Song = str_replace(Song, "\u00a0", " "))Chunk time: 0.01 secs
4 Artist
We can do a similar thing to have a look at the characters in the artist field.
artist_chars <- requestival$Artist %>%
str_extract_all(boundary("character")) %>%
unlist() %>%
sort() %>%
unique()
artist_chars %>%
map_int(function(.x) {utf8ToInt(.x)[1]}) %>%
Unicode::u_char_info() %>%
mutate(Character = artist_chars) %>%
select(Character, Code, Name)Chunk time: 0.07 secs
This looks ok so I don’t think we need to do anything here.
5 Release
Let’s have a look at the characters in the release field as well.
release_chars <- requestival$Release %>%
str_extract_all(boundary("character")) %>%
unlist() %>%
sort() %>%
unique()
release_chars %>%
map_int(function(.x) {utf8ToInt(.x)[1]}) %>%
Unicode::u_char_info() %>%
mutate(Character = release_chars) %>%
select(Character, Code, Name)Chunk time: 0.09 secs
There are some more unusual characters here but they also look to be correct so we will leave them for now.
6 Links
The remaining fields that we scraped are links to places where you can listen to each song. We probably don’t want to mess with these too much but let’s take a look.
6.1 YouTube
The YouTube URLs look something like this: https://www.youtube.com/results?search_query=BRONSON%20HEART%20ATTACK%20{Ft.%20lau.ra}
This is just a link a YouTube search results page for a query made up of the artist and song name. It might be useful to be able to access the query part so let’s make that into a new column.
requestival <- requestival %>%
mutate(YouTubeQuery = str_remove(YouTube, "^.*="))
requestivalChunk time: 0.79 secs
6.2 Spotify
The Spotify URLs are similar: https://play.spotify.com/search/results/artist:BRONSON%20track:HEART%20ATTACK%20%7BFt.%20lau.ra%7D
We can make a similar column for the Spotify query.
requestival <- requestival %>%
mutate(SpotifyQuery = str_remove(Spotify, "^.*/results/"))
requestivalChunk time: 0.89 secs
6.3 Unearthed
The Unearthed links are a bit different: https://www.triplejunearthed.com/node/144546
These are direct links to artist pages on the Unearthed website rather than searches. There probably isn’t much useful information in these but it would be nice to know which artists are on Unearthed so let’s make a boolean column to represent this.
requestival <- requestival %>%
mutate(IsUnearthed = !is.na(Unearthed))
requestivalChunk time: 0.86 secs
7 Selecting columns
Now that we have tidied up the individual columns we can tidy up the table as a whole. For example the “File” field isn’t much use now that we have extracted the date information and the “Day”, “Time” and “DateTime” columns are a bit redundant. The times are also inconsistent because we have converted DateTime to the Australian time zone but the others are still in European time. We might also like to rearrange and rename some of the columns.
requestival <- requestival %>%
select(
DateTime,
Song,
Artist,
Release,
IsUnearthed,
UnearthedURL = Unearthed,
SpotifyQuery,
SpotifyURL = Spotify,
YouTubeQuery,
YouTubeURL = YouTube
) %>%
arrange(DateTime)
requestivalChunk time: 0.83 secs
8 Filtering
The final step in our tidying is to filter out some of the songs. The Requestival officially runs between 6 am and 9 pm from Monday 25 May to Sunday 31 May. On the final day it actually ends a bit earlier at 6 pm. We are only interested in songs played during this period so we need to filter out other times. There is probably a cleaner way to do this but I’m just going to use a big ol’ logical statement.
tz <- "Australia/Sydney" # This is just to save space
times <- tribble(
~Start, ~End,
ymd_hm("2020-05-25 06:00", tz = tz), ymd_hm("2020-05-25 21:00", tz = tz),
ymd_hm("2020-05-26 06:00", tz = tz), ymd_hm("2020-05-26 21:00", tz = tz),
ymd_hm("2020-05-27 06:00", tz = tz), ymd_hm("2020-05-27 21:00", tz = tz),
ymd_hm("2020-05-28 06:00", tz = tz), ymd_hm("2020-05-28 21:00", tz = tz),
ymd_hm("2020-05-29 06:00", tz = tz), ymd_hm("2020-05-29 21:00", tz = tz),
ymd_hm("2020-05-30 06:00", tz = tz), ymd_hm("2020-05-30 21:00", tz = tz),
ymd_hm("2020-05-31 06:00", tz = tz), ymd_hm("2020-05-31 18:00", tz = tz)
)
requestival <- requestival %>%
filter(
(DateTime >= times$Start[1] & DateTime <= times$End[1]) |
(DateTime >= times$Start[2] & DateTime <= times$End[2]) |
(DateTime >= times$Start[3] & DateTime <= times$End[3]) |
(DateTime >= times$Start[4] & DateTime <= times$End[4]) |
(DateTime >= times$Start[5] & DateTime <= times$End[5]) |
(DateTime >= times$Start[6] & DateTime <= times$End[6]) |
(DateTime >= times$Start[7] & DateTime <= times$End[7])
)Chunk time: 0.11 secs
It would be easy to miss this up let’s make a quick plot of the play times to check what songs we have kept.
ggplot(requestival, aes(x = DateTime, y = 0)) +
geom_jitter(width = 0) +
geom_vline(data = times, aes(xintercept = Start), colour = "red") +
geom_vline(data = times, aes(xintercept = End), colour = "blue") +
theme_minimal()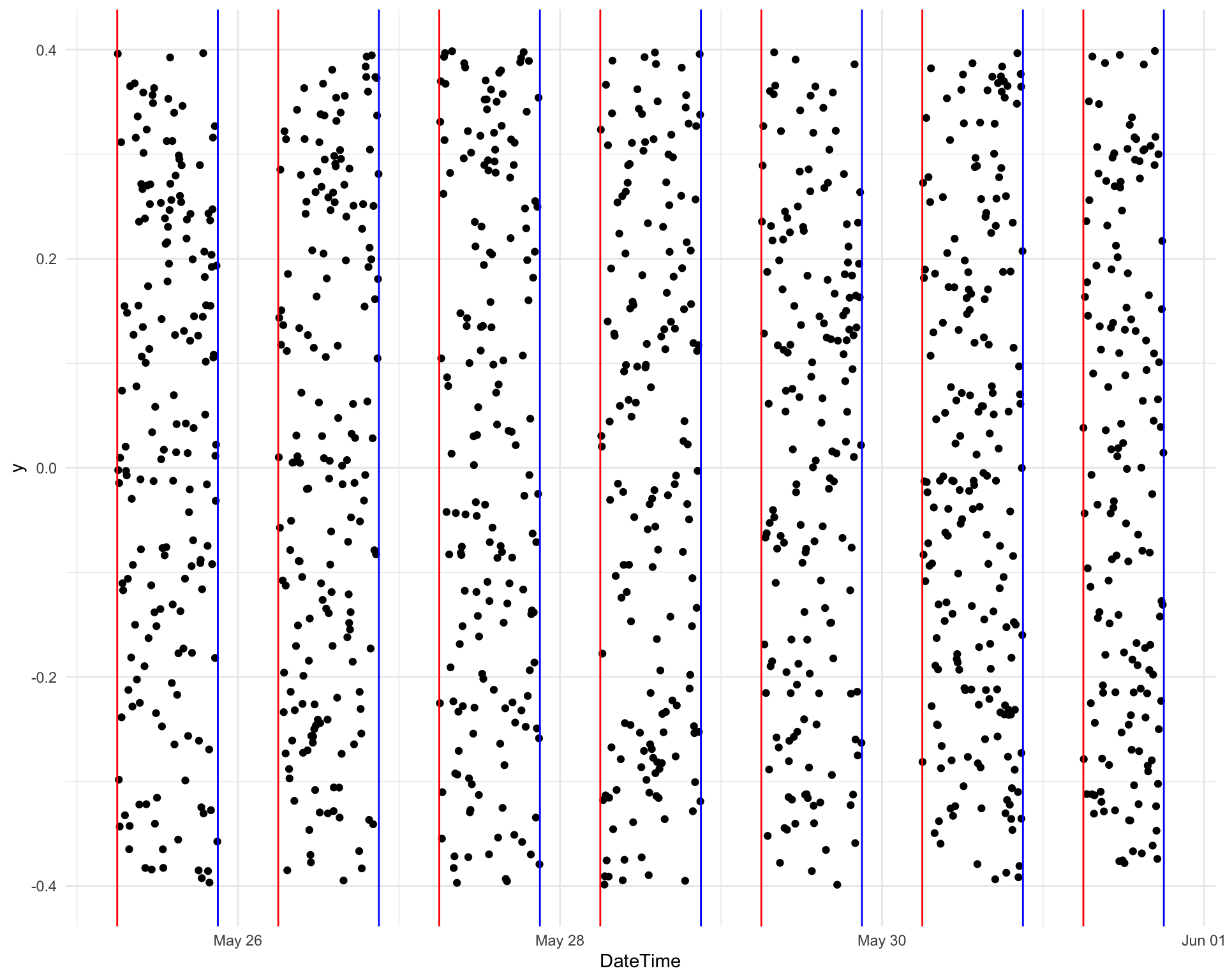
| Version | Author | Date |
|---|---|---|
| f53e0cb | Luke Zappia | 2020-05-30 |
Chunk time: 0.47 secs
That looks pretty good 🎉!
The final dataset has 10 columns and 1187 rows. Let’s save it to use for future analysis.
write_tsv(requestival, PATHS$tidied)
requestivalChunk time: 0.44 secs
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.0.0 (2020-04-24)
os macOS Catalina 10.15.4
system x86_64, darwin17.0
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Europe/Berlin
date 2020-06-01
─ Packages ───────────────────────────────────────────────────────────────────
! package * version date lib source
P assertthat 0.2.1 2019-03-21 [?] CRAN (R 4.0.0)
P backports 1.1.7 2020-05-13 [?] CRAN (R 4.0.0)
P base64enc 0.1-3 2015-07-28 [?] CRAN (R 4.0.0)
P blob 1.2.1 2020-01-20 [?] CRAN (R 4.0.0)
P broom 0.5.6 2020-04-20 [?] CRAN (R 4.0.0)
P cellranger 1.1.0 2016-07-27 [?] standard (@1.1.0)
P cli 2.0.2 2020-02-28 [?] CRAN (R 4.0.0)
P colorspace 1.4-1 2019-03-18 [?] standard (@1.4-1)
P conflicted * 1.0.4 2019-06-21 [?] standard (@1.0.4)
P crayon 1.3.4 2017-09-16 [?] CRAN (R 4.0.0)
P DBI 1.1.0 2019-12-15 [?] CRAN (R 4.0.0)
P dbplyr 1.4.4 2020-05-27 [?] CRAN (R 4.0.0)
P digest 0.6.25 2020-02-23 [?] CRAN (R 4.0.0)
P dplyr * 0.8.5 2020-03-07 [?] CRAN (R 4.0.0)
P ellipsis 0.3.1 2020-05-15 [?] CRAN (R 4.0.0)
P evaluate 0.14 2019-05-28 [?] standard (@0.14)
P fansi 0.4.1 2020-01-08 [?] CRAN (R 4.0.0)
P farver 2.0.3 2020-01-16 [?] CRAN (R 4.0.0)
P forcats * 0.5.0 2020-03-01 [?] CRAN (R 4.0.0)
P fs * 1.4.1 2020-04-04 [?] CRAN (R 4.0.0)
P generics 0.0.2 2018-11-29 [?] standard (@0.0.2)
P genius 2.2.2 2020-05-28 [?] CRAN (R 4.0.0)
P ggplot2 * 3.3.1 2020-05-28 [?] CRAN (R 4.0.0)
P git2r 0.27.1 2020-05-03 [?] CRAN (R 4.0.0)
P glue * 1.4.1 2020-05-13 [?] CRAN (R 4.0.0)
P gtable 0.3.0 2019-03-25 [?] standard (@0.3.0)
P haven 2.3.0 2020-05-24 [?] CRAN (R 4.0.0)
P here * 0.1 2017-05-28 [?] standard (@0.1)
P hms 0.5.3 2020-01-08 [?] CRAN (R 4.0.0)
P htmltools 0.4.0 2019-10-04 [?] standard (@0.4.0)
P httpuv 1.5.3.1 2020-05-26 [?] CRAN (R 4.0.0)
P httr 1.4.1 2019-08-05 [?] standard (@1.4.1)
P janeaustenr 0.1.5 2017-06-10 [?] CRAN (R 4.0.0)
P jsonlite 1.6.1 2020-02-02 [?] CRAN (R 4.0.0)
P knitr 1.28 2020-02-06 [?] CRAN (R 4.0.0)
P labeling 0.3 2014-08-23 [?] standard (@0.3)
P later 1.0.0 2019-10-04 [?] standard (@1.0.0)
P lattice 0.20-41 2020-04-02 [3] CRAN (R 4.0.0)
P lifecycle 0.2.0 2020-03-06 [?] CRAN (R 4.0.0)
P lubridate * 1.7.8 2020-04-06 [?] CRAN (R 4.0.0)
P magrittr 1.5 2014-11-22 [?] CRAN (R 4.0.0)
P Matrix 1.2-18 2019-11-27 [3] CRAN (R 4.0.0)
P memoise 1.1.0 2017-04-21 [?] standard (@1.1.0)
P modelr 0.1.8 2020-05-19 [?] CRAN (R 4.0.0)
P munsell 0.5.0 2018-06-12 [?] standard (@0.5.0)
P nlme 3.1-147 2020-04-13 [3] CRAN (R 4.0.0)
P pillar 1.4.4 2020-05-05 [?] CRAN (R 4.0.0)
P pkgconfig 2.0.3 2019-09-22 [?] CRAN (R 4.0.0)
P plyr 1.8.6 2020-03-03 [?] CRAN (R 4.0.0)
P promises 1.1.0 2019-10-04 [?] standard (@1.1.0)
P purrr * 0.3.4 2020-04-17 [?] CRAN (R 4.0.0)
P R6 2.4.1 2019-11-12 [?] CRAN (R 4.0.0)
P Rcpp 1.0.4.6 2020-04-09 [?] CRAN (R 4.0.0)
P readr * 1.3.1 2018-12-21 [?] standard (@1.3.1)
P readxl 1.3.1 2019-03-13 [?] standard (@1.3.1)
P reprex 0.3.0 2019-05-16 [?] standard (@0.3.0)
P reshape2 1.4.4 2020-04-09 [?] CRAN (R 4.0.0)
P rlang 0.4.6 2020-05-02 [?] CRAN (R 4.0.0)
P rmarkdown 2.1 2020-01-20 [?] CRAN (R 4.0.0)
P rprojroot 1.3-2 2018-01-03 [?] CRAN (R 4.0.0)
P rstudioapi 0.11 2020-02-07 [?] CRAN (R 4.0.0)
P rvest * 0.3.5 2019-11-08 [?] standard (@0.3.5)
P scales 1.1.1 2020-05-11 [?] CRAN (R 4.0.0)
sessioninfo 1.1.1 2018-11-05 [3] CRAN (R 4.0.0)
P SnowballC 0.7.0 2020-04-01 [?] CRAN (R 4.0.0)
P spotifyr * 2.1.1 2019-07-13 [?] CRAN (R 4.0.0)
P stringi 1.4.6 2020-02-17 [?] CRAN (R 4.0.0)
P stringr * 1.4.0 2019-02-10 [?] CRAN (R 4.0.0)
P tibble * 3.0.1 2020-04-20 [?] CRAN (R 4.0.0)
P tidyr * 1.1.0 2020-05-20 [?] CRAN (R 4.0.0)
P tidyselect 1.1.0 2020-05-11 [?] CRAN (R 4.0.0)
P tidytext 0.2.4 2020-04-17 [?] CRAN (R 4.0.0)
P tidyverse * 1.3.0 2019-11-21 [?] standard (@1.3.0)
P tokenizers 0.2.1 2018-03-29 [?] CRAN (R 4.0.0)
P Unicode 13.0.0-1 2020-03-16 [?] CRAN (R 4.0.0)
P vctrs 0.3.0 2020-05-11 [?] CRAN (R 4.0.0)
P whisker 0.4 2019-08-28 [?] standard (@0.4)
P withr 2.2.0 2020-04-20 [?] CRAN (R 4.0.0)
P workflowr 1.6.2 2020-04-30 [?] CRAN (R 4.0.0)
P xfun 0.14 2020-05-20 [?] CRAN (R 4.0.0)
P xml2 * 1.3.2 2020-04-23 [?] CRAN (R 4.0.0)
P yaml 2.2.1 2020-02-01 [?] CRAN (R 4.0.0)
[1] /Users/luke.zappia/Documents/Projects/requestival/renv/library/R-4.0/x86_64-apple-darwin17.0
[2] /private/var/folders/rj/60lhr791617422kqvh0r4vy40000gn/T/RtmpQWp4dI/renv-system-library
[3] /Library/Frameworks/R.framework/Versions/4.0/Resources/library
P ── Loaded and on-disk path mismatch.Chunk time: 0.2 secs